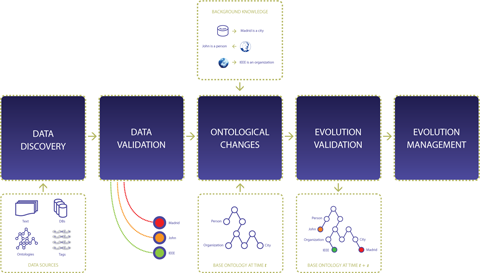
Our ontology evolution framework is designed to cover a comprehensive cycle of ontology evolution. It is formed of five different components: Data Discovery, Data Validation, Ontological Changes, Evolution Validation, and Evolution Management.
Click to Enlarge
For a more detailed view, please check: [1] or [2]
One way to detect new knowledge to be added to the base ontology is by contrasting it to information contained in external domain and application specific sources, such as text corpora, databases or other ontologies. Text documents contain unstructured data, hence require information extraction or ontology learning tools. External ontologies and databases present a more structured source of information, where concepts, relations and instances are explicitly encoded in a well-defined structure. However, a translation should be applied on exploited ontologies to ensure language compatibility with the base ontology. In the case of databases, a transformation should be performed to encapsulate the database schema and entities in an ontology compatible language.
One way to validate discovered information is by applying a set of heuristic rules. For example, most of the one and two-letter concepts extracted from a corus are meaningless and should be discarded. Ontologies and databases do not need this kind of low level quality check as the content structure is more trusted.
The validated schema and instance elements are passed to the the relation discovery process, for resolving the links to existing knowledge. We propose a gradual matching technique, which starts from the simplest and quickest methods, to the more complex and time-consuming ones: (1) The process starts with a string matching to identify possible equivalence with existing ontology terms. (2) If no equivalence is resolved, i.e. the term is new to the ontology, subsumption relations are attempted to be discovered based on WordNet's senses hierarchy. (3) If no relation is discovered at the level of WordNet, we rely on online ontologies for a richer relation discovery process. (4) As a final resort, we harvest all the web through search engines APIs, coupled with the use of lexical patterns. In case no relation is found at the final level, the extracted term is discarded, or could be possibly passed for manual check. We use the discovered relation path for performing the changes on the ontology.
Performing ontological changes could generate some problems such as conflicting statements, data duplication and time related inconsistencies. We deal with these problems at the level of the evolution validation component, formed of the consistency and duplication checks, as well as the temporal reasoning process.
The approved ontology is passed to the evolution management component. In this component, the changes performed on the ontology are recorded to ensure functionalities such as tracing or rolling back changes. The changes are then propagated to dependent ontologies and applications. Administrator control is supplied for monitoring purposes, setting the evolution parameters and resolving any additional problem.







